I've been programming music for a long time. In the beginning I played with FastTracker 2 and later moved on to Cubase and Ableton Live, all running on some Microsoft OS (yuck).
Then finally I landed on Bitwig because it's awesome and runs on Linux!
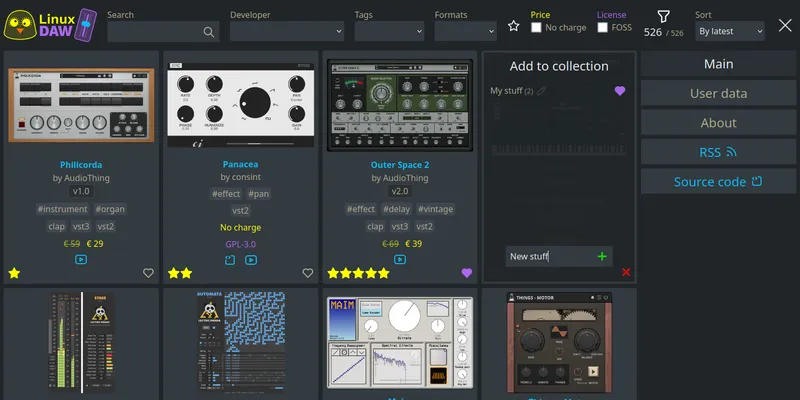
Problem was, it was hard to find proper info about audio production software for Linux, so about a year ago I set out to do something about it and created https://linuxdaw.org.
My drive for doing this was a wish to upgrade my Vue knowledge from version 2 to 3, and the best way to learn a piece of software is to find a fun pet project. I started coding right after christmas, you know, those boring days when nothing is really happening.
It took me about a week of late evenings to get some kind of prototype up and then some days to slowly add content. I've been updating it ever since with some good help from the community. I'm looking at you Amadeus, thanks for your contributions! 😃
One of the goals of the site is to use modern web technology as this is something that interests me a lot.
It was also important to me to make it as optimized and lightweight as possible, because there's already enough of slow bloated sites out there. So I decided on keeping it client side only, meaning all the data is loaded into and stored in the browser only once. No DB. No XHR calls.
All entries (544 at the time of writing this) are fetched on first load and handled by code running in the browser. This is how a typical entry is stored
{
name: 'Wolf Shaper',
developer: 'Misc',
developers: ['Wolf Plugins', 'Patrick Desaulniers'],
url: 'https://wolf-plugins.github.io/wolf-shaper/',
image: 'https://wolf-plugins.github.io/wolf-shaper/images/screenshot.png',
source: 'https://github.com/wolf-plugins/wolf-shaper',
price: 'No charge',
tags: ['effect', 'distortion', 'waveshaper'],
formats: ['clap', 'lv2', 'vst3', 'vst2'],
license: 'GPL-3.0',
created: '2023-01-03',
},There was a risk in this though, how would it scale? I had no way of really knowing until trying, so lets go I thought. Well, so far so good. Things are still pretty snappy and as far as I know there isn't any problems.
Images are big static assets so it's a bad idea to store them in the repository. They are downloaded locally with a Node.js script I made and then synced to the server using rsync.
I implemented 3 versions of each image (small, medium and original size) so that users wouldn't have to load huge files when scrolling through the lists. The original image only shows on user demand.
The download script does a bit of this and that, but the gist of it is this
// Download
const response = await fetch(imageUrl)
const blob = await response.blob()
const arrayBuffer = await blob.arrayBuffer()
buffer = Buffer.from(arrayBuffer)
// Save to disk
await sharp(buffer).trim(trimOptions).toFile(files.large)
await sharp(buffer).trim(trimOptions).resize(660, 440, { fit: 'inside' }).toFile(files.medium)
await sharp(buffer).trim(trimOptions).resize(420, 280, { fit: 'inside' }).toFile(files.small)As the number of entries started increasing I quickly realized I needed some kind of lazy loading, so I implemented a "load as you scroll" algorithm for the list. It goes a little something like this
onMounted(() => {
// Lazy load elements when scrolling is near bottom
window.addEventListener('scroll', () => {
if (store.filter.lazyloadMax < store.filter.quantity) {
if ((window.innerHeight + window.scrollY) >= document.body.offsetHeight * 0.95) {
store.filter.lazyloadMax += 12
}
}
});
})This, together with the filter, is working quite well and it's pretty fast and easy to find what you're looking for.
The full source code of the site and all data is ofc hosted on Codeberg.
More contributions are most welcome, especially when it comes to content.